Confluent Cloud mit Spring Boot und Avro in 5 Minuten

Die Hauptaufgabe von Kafka besteht darin, Daten sicher und schnell von Punkt A nach Punkt B zu bringen. Kafka geht aber noch weiter, denn eine der größten Fehlerquellen kann fast vollständig ausgeschlossen werden wenn man Kafka mit den richtigen Tools kombiniert.
Felder die leer sind aber eigentlich nicht leer sein sollten.
Felder die nicht (mehr) vorhanden sind, aber dein Team benötigt genau diese Daten.
Felder die eigentlich als Datum klassifiziert sind, die aber "Müller" als Wert liefern.
Was ist da nur los?
Willkommen in der Welt der Datenverträge. Mit Datenverträgen (Data Contracts) ist es wie im wirklichen Leben. Wo kein Kläger, da kein Richter. Wenn niemand auf die Einhaltung von Verträgen besteht, dann läuft die Struktur der Daten zwangsläufig Schritt für Schritt aus dem Ruder.
Mit Kafka und der Schema Registry besteht die Möglichkeit, auf die Einhaltung von Verträgen zu bestehen.
Verträge, Schemas und Registries. Worum gehts hier?
In diesem Artikel behandeln wir den einfachsten Fall eines Vertrages und erzwingen eine Struktur unserer Nachrichten in Kafka. Wir verwenden hierfür Avro - ein binäres Protokoll das wir bei einem Großteil unserer Kunden im Einsatz haben.
Statt lange zu beschreiben wie die Arbeit mit Schemas, Data Contracts und der Schema Registry funktioniert probieren wir das Ganze einfach aus.
Der Artikel basiert auf dem letzten Artikel, in dem wir eine Umgebung mit Confluent Cloud und Spring Boot in weniger als 5 Minuten aufgesetzt haben.
In dem verlinkten Artikel zeigen wir dir, wir du eine einfache Confluent Cloud Umgebung aufsetzt und dich mit einem Spring Boot Client darauf verbindest.
In diesem Artikel lernst du, wie du dem Spring Boot Client beibringst, sich an die Datenverträge zu halten die in Kafka bzw. der Schema Registry definiert wurden. Wir behandeln die Details zur Schema Registry in einem eigenen Artikel und fokussieren uns zunächst auf die praktische Anwendung.
Achtung - für den Rest des Artikels gehe ich davon aus, dass die Umgebung aus dem letzten Artikel bereits da ist.
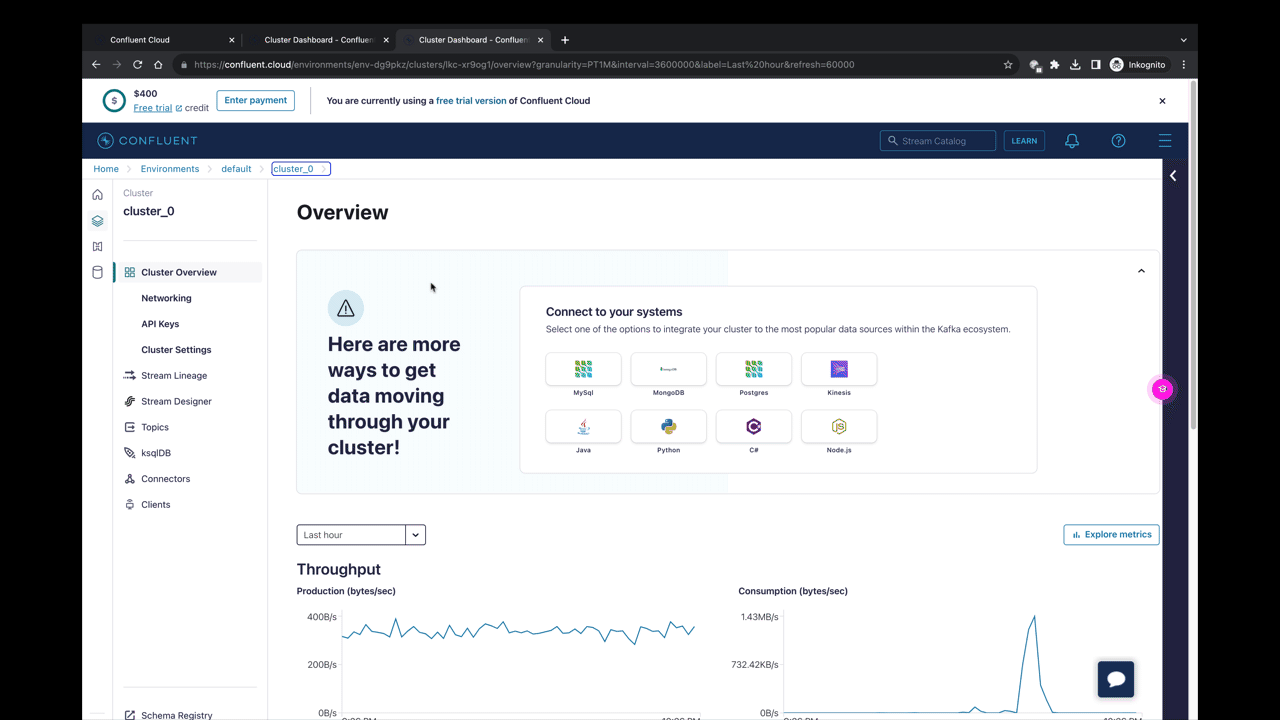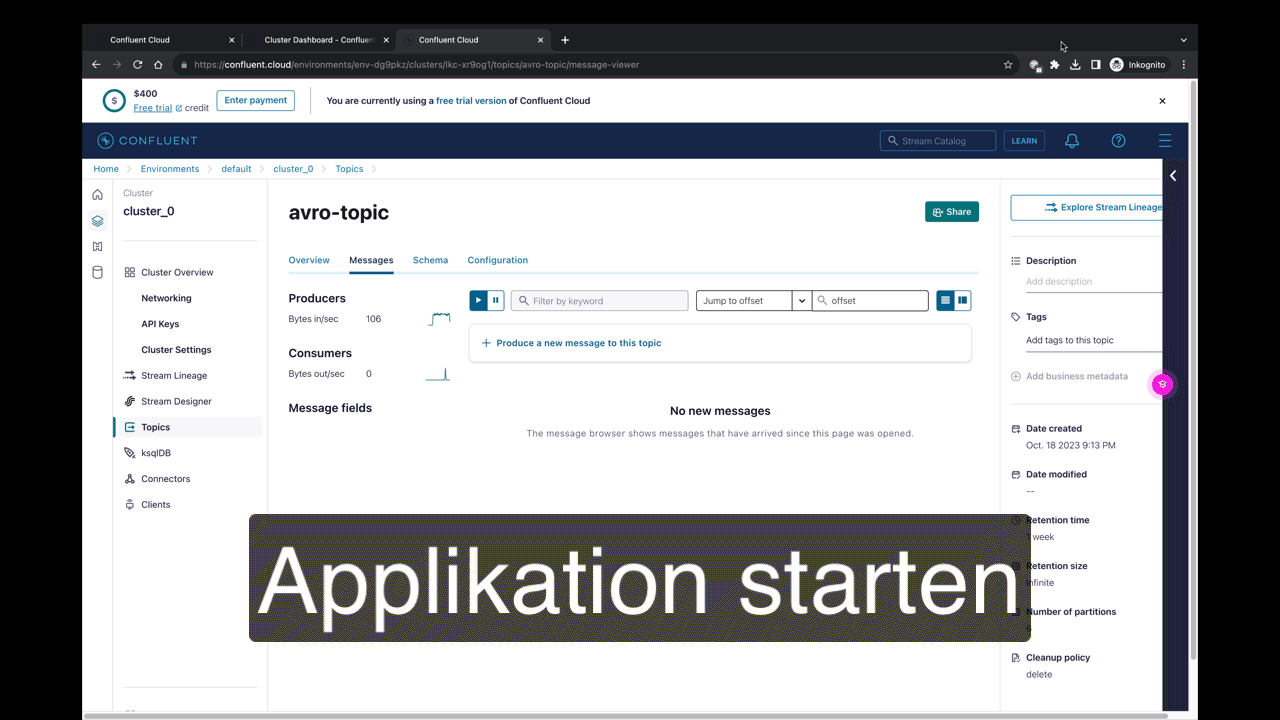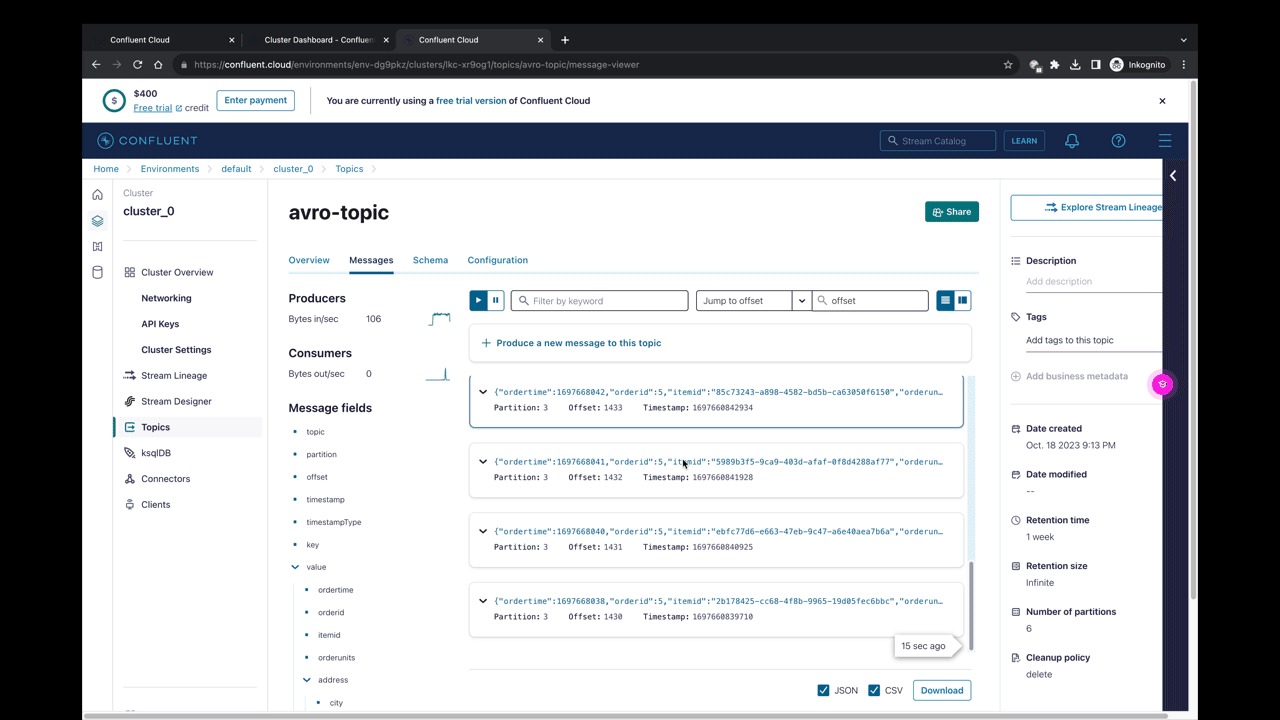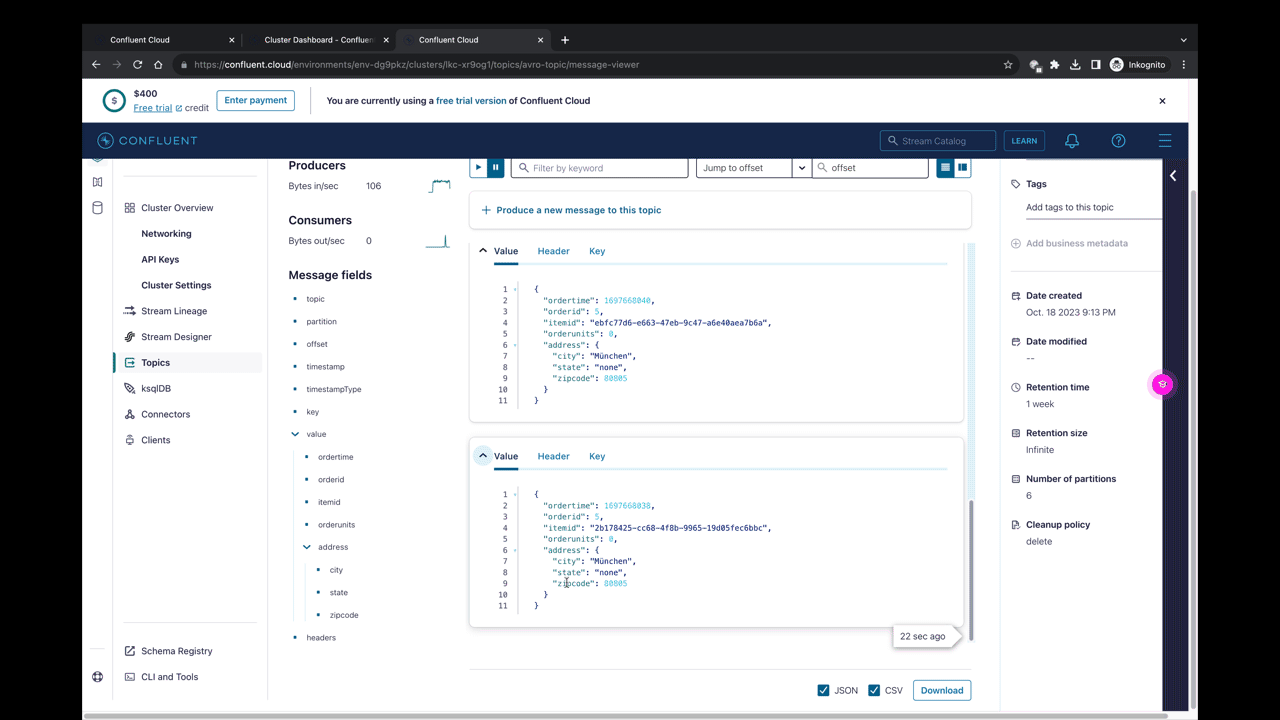
Zuerst erzeugen wir ein neues Topic direkt über die Confluent Cloud Oberfläche.
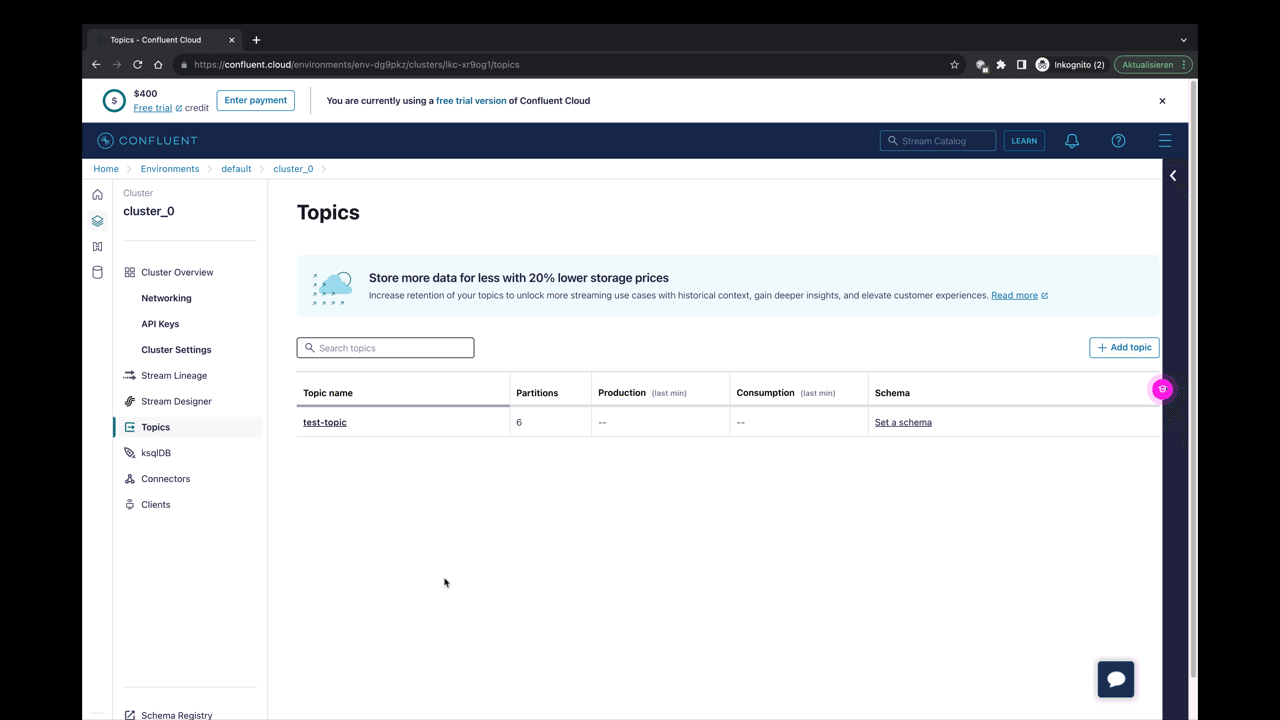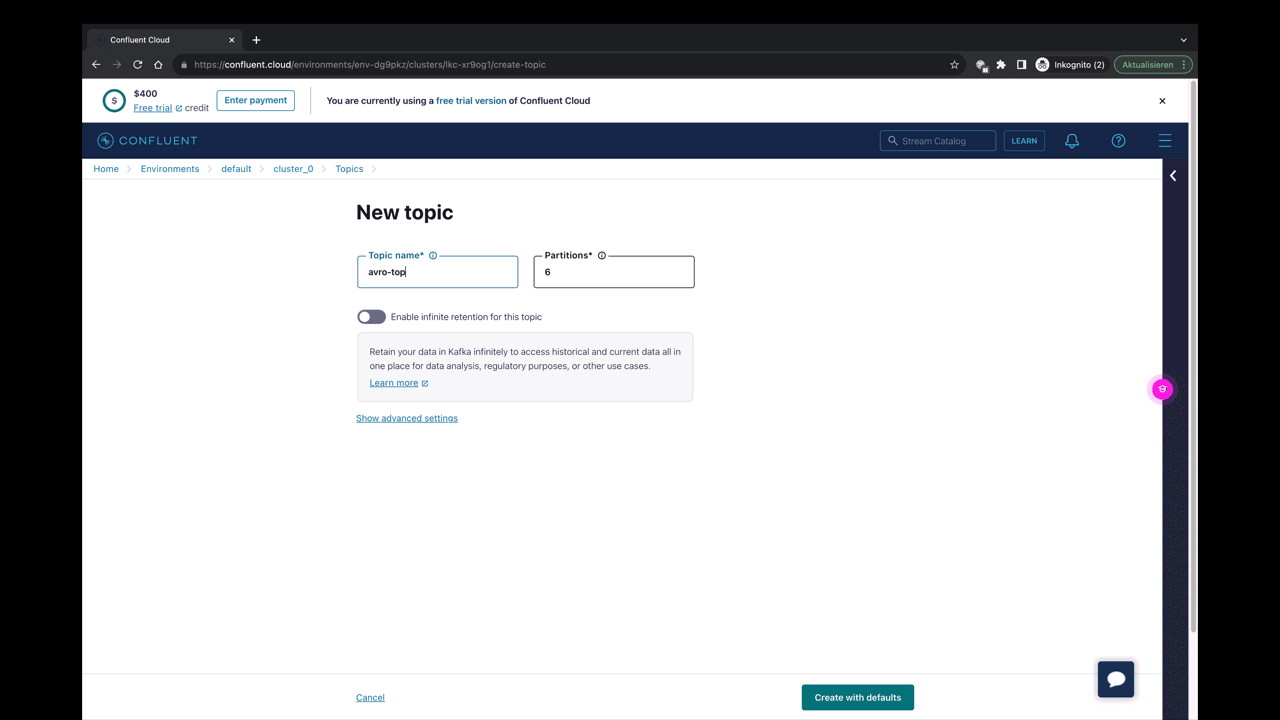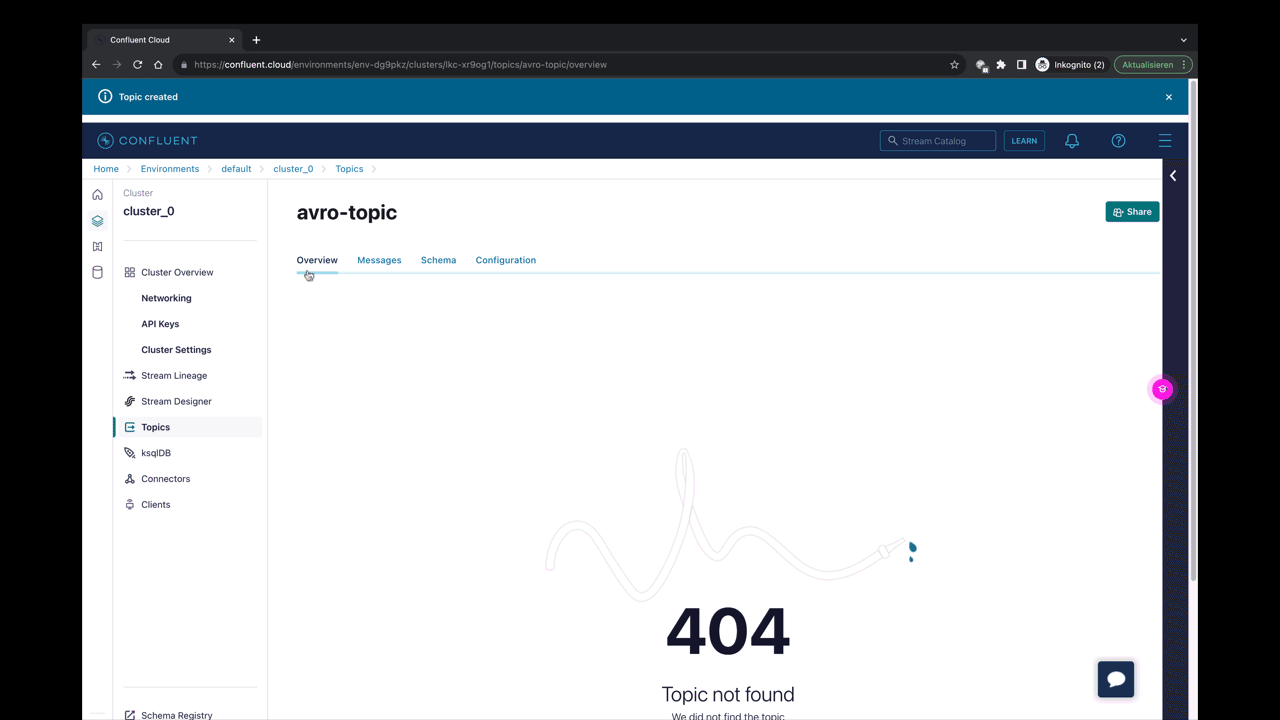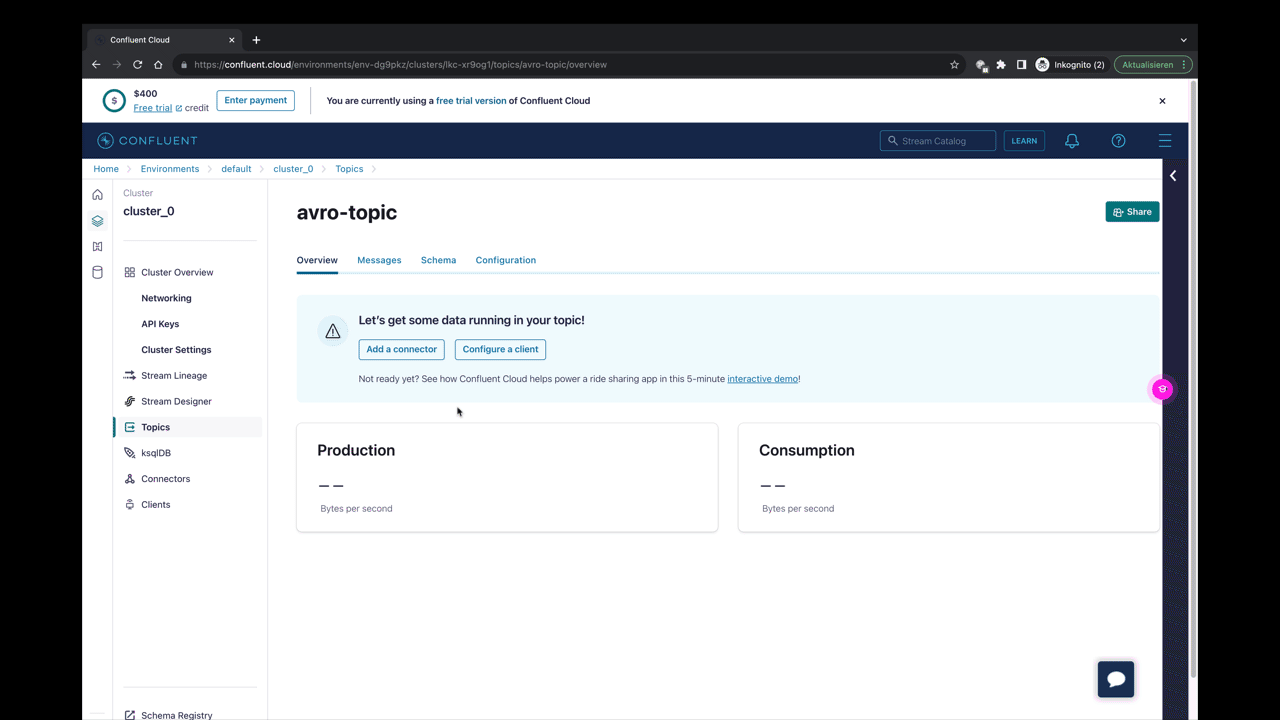
Wir haben jetzt die Möglichkeit, für jedes Topic ein oder mehrere Schemas zu hinterlegen. Das geht entweder direkt über die UI oder im nächsten Schritt über einen Connector.
DataGen Connector konfigurieren
Wir hatten im letzten Artikel bereits den DataGen Connector verwendet um massenweise Testdaten für unseren Kafka Cluster zu generieren. Wir können den Connector auch verwenden um Avro Daten statt JSON zu generieren. Der große Vorteil ist, dass der DataGen Connector die Schemas für ein Topic automatisch registriert, so dass wir damit arbeiten können.
Du siehst im Beispiel hier dass das Schema im Topic bereits registriert ist, sobald der DataGen Connector gestartet wurde.
Der Vertrag wurde geschlossen.
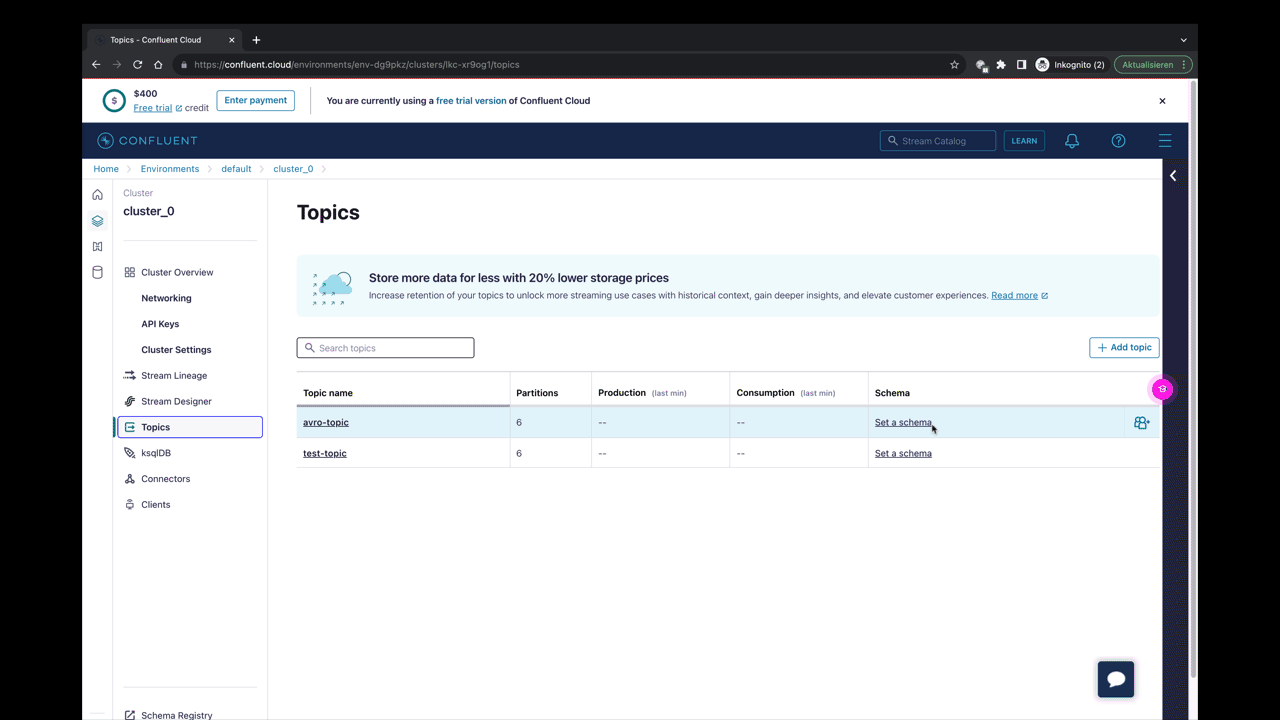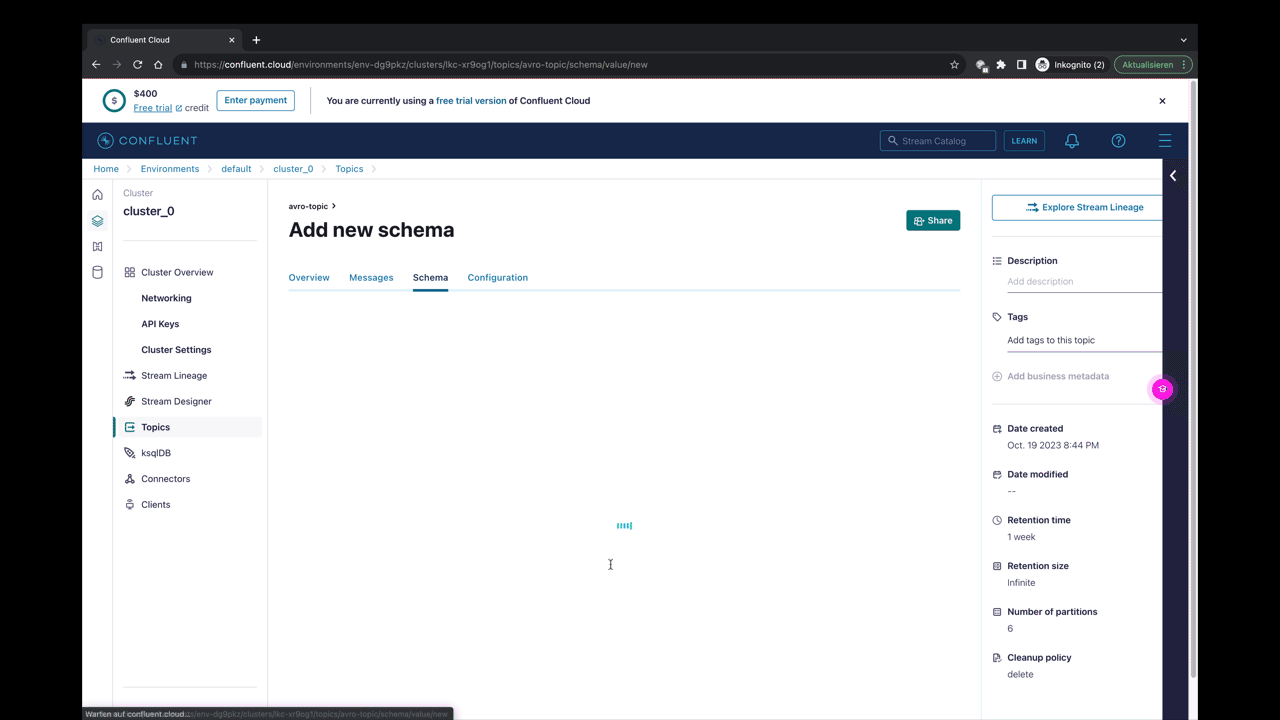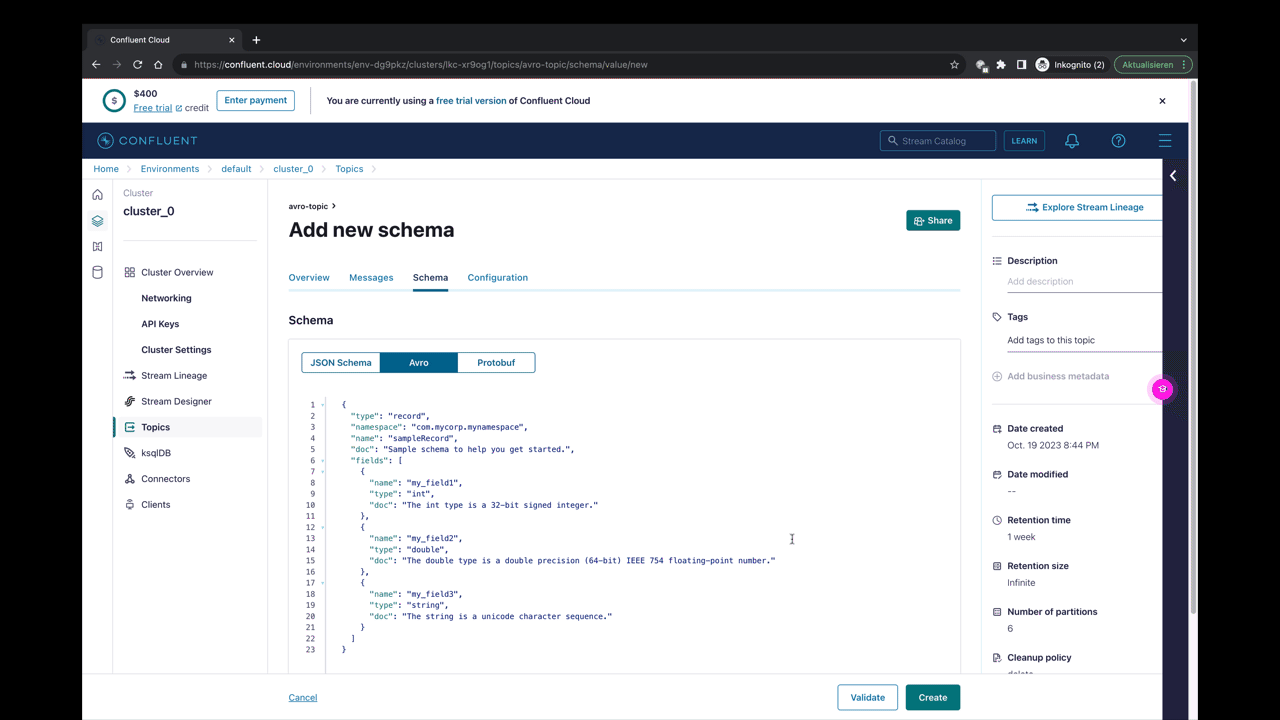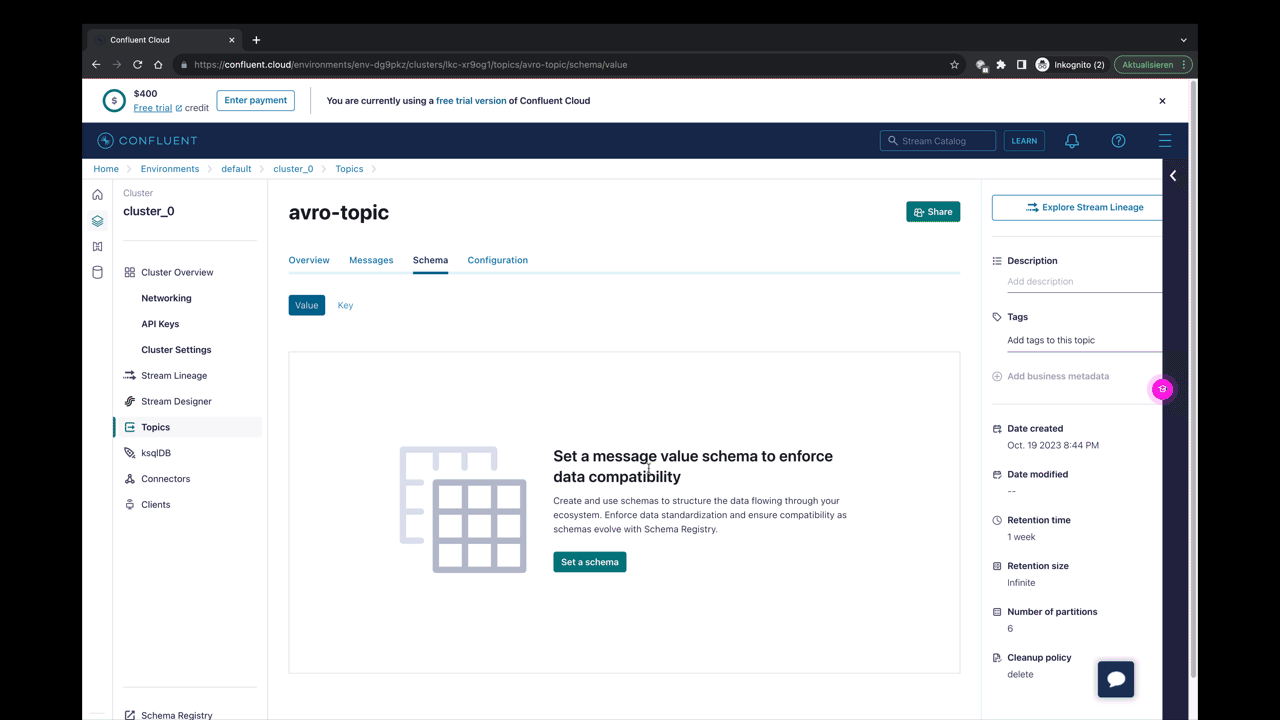
Das Schema
Ein Avro Schema ist eine einfache JSON Definition die die Struktur der Daten beschreibt.
Das hier abgebildete Schema (das auch vom Connector registriert wurde) beschreibt die Struktur eines Objektes "orders" und definiert beispielsweise dass ein "orders" Objekt ein Feld orderid definieren muss und zwar vom typ int.
Wenn dein Team also mit dieser Struktur arbeitet kann sich jeder darauf verlassen, dass der Typ dieses Feldes immer korrekt gesetzt ist.
Wer jemals anders arbeiten musste weiß sofort, wie wertvoll es ist, sich darauf verlassen zu können.
{ "connect.name": "ksql.orders", "name": "orders", "namespace": "ksql", "type": "record", "fields": [ { "name": "ordertime", "type": "long" }, { "name": "orderid", "type": "int" }, { "name": "itemid", "type": "string" }, { "name": "orderunits", "type": "double" }, { "name": "address", "type": { "connect.name": "ksql.address", "fields": [ { "name": "city", "type": "string" }, { "name": "state", "type": "string" }, { "name": "zipcode", "type": "long" } ], "name": "address", "type": "record" } } ] }
Avro & Code Generierung
In diesem Abschnitt bringen wir dem Spring Boot Client bei, Messages beim Schreiben in Kafka mit Avro zu serialisieren bzw. beim Lesen aus Kafka mit Avro zu deserialisieren.
Hierfür holen wir uns zunächst manuell das Schema aus der Schema Registry und kopieren es in die Applikation. Das lässt sich auch über ein Maven Plugin bzw. im Code automatisieren. Für den Moment reicht aber der manuelle Prozess um schnell zu experimentieren.
Warum brauchen wir das Schema lokal im Client?
Aus dem Schema generieren wir Code und die notwendigen Klassen, um das "orders" Objekt erzeugen zu können. Damit stellt der Compiler bereits sicher, dass der Datenvertrag eingehalten wird.
Cool oder?
Für die Codegenerierung nutzen wir das einfache avro-maven-plugin und deklarieren es in der pom.xml
In der Konfiguration im Attribut sourceDirectory definieren wir, wo im Projekt die Avro-Schemas zu finden sind um Code daraus zu generieren.
<plugin> <groupId>org.apache.avro</groupId> <artifactId>avro-maven-plugin</artifactId> <version>1.11.2</version> <executions> <execution> <phase>generate-sources</phase> <goals> <goal>schema</goal> </goals> <configuration> <!-- source folder avro schema definitions --> <sourceDirectory>src/main/avro</sourceDirectory> <!-- target folder --> <outputDirectory>${project.build.directory}/generated-sources</outputDirectory> </configuration> </execution> </executions> </plugin>
Jetzt laden wir Schema einfach per Download aus der UI und legen es im Classpath ab. Direkt nach einem "mvn package" sind die erzeugten Klassen verfügbar und können im KafkaConsumer direkt verwendet werden. (Zum Consumer selber kommen wir gleich).
Spring Boot & Avro Serializer / Deserializer
Im letzten Schritt müssen wir der Spring Boot Kafka Integration beibringen, dass Messages automatisch mit Avro serialisiert und deserialisiert werden müssen. Hierfür reicht es in der application.properties die Serializer/Deserializer für Consumer und Producer zu konfigurieren.
# producer avro config spring.kafka.producer.value-serializer=io.confluent.kafka.serializers.KafkaAvroSerializer # consumer avro config spring.kafka.consumer.value-deserializer=io.confluent.kafka.serializers.KafkaAvroDeserializer spring.kafka.consumer.properties.specific.avro.reader=true
Die hier referenzierten KafkaAvroSerializer und KafkaAvroDeserializer befinden sich in der kafka-avro-serializer Library von Confluent die wir ebenfalls in der pom.xml deklarieren.
<dependency> <groupId>io.confluent</groupId> <artifactId>kafka-avro-serializer</artifactId> <version>5.3.0</version> </dependency> <dependency> <groupId>org.apache.avro</groupId> <artifactId>avro</artifactId> <version>1.11.2</version> </dependency>
Starten wir die Applikation sehen wir sofort eine Unauthorized Exception.
Caused by: io.confluent.kafka.schemaregistry.client.rest.exceptions.RestClientException: Unauthorized; error code: 401
Woher kommt die denn jetzt?
Die Avro-Serializer und Deserializer verbinden sich auf die Schema Registry und prüfen, welche Schemas dort für die Topics hinterlegt sind und prüfen auch, ob die lokal verwendeten Schema mit denen in der Registry kompatibel sind.
Über Schema Kompatibilität und Schema Evolution lässt sich ein ganzer Artikel, wenn nicht ein ganzes Buch füllen, daher verschieben wir dies auf einen der nächsten Artikel. Details dazu finden sich aber bereits hier
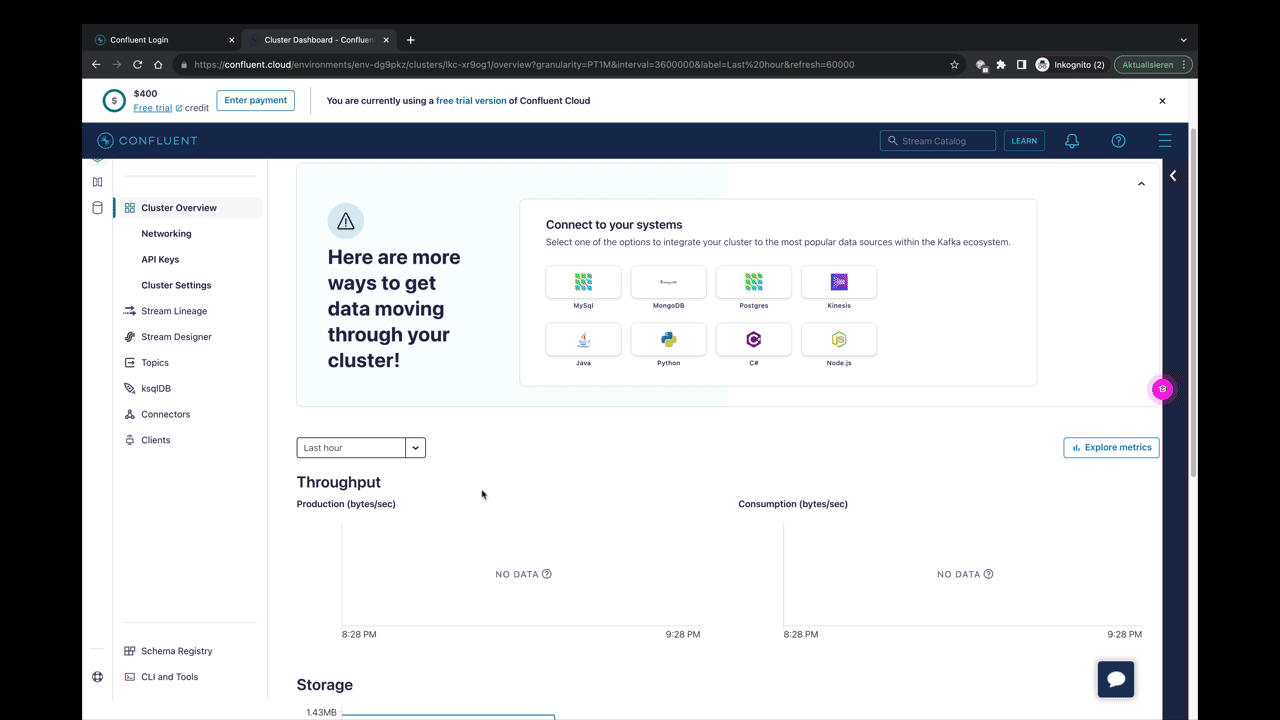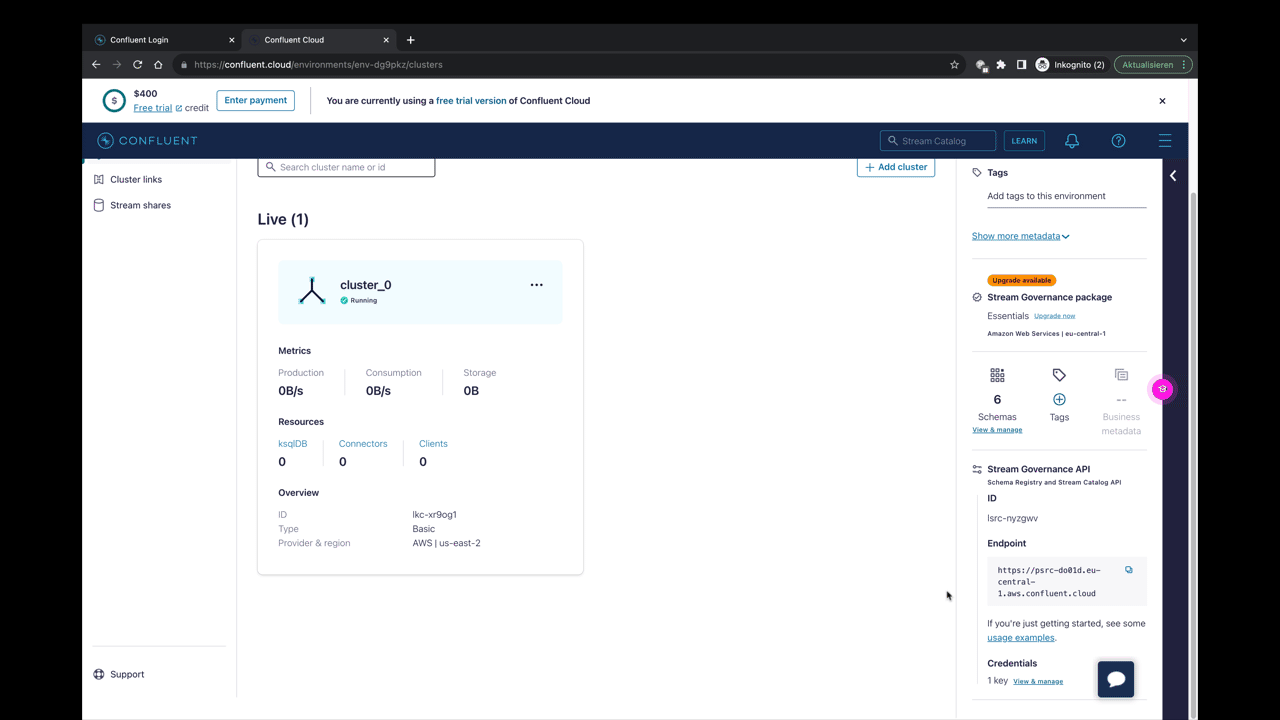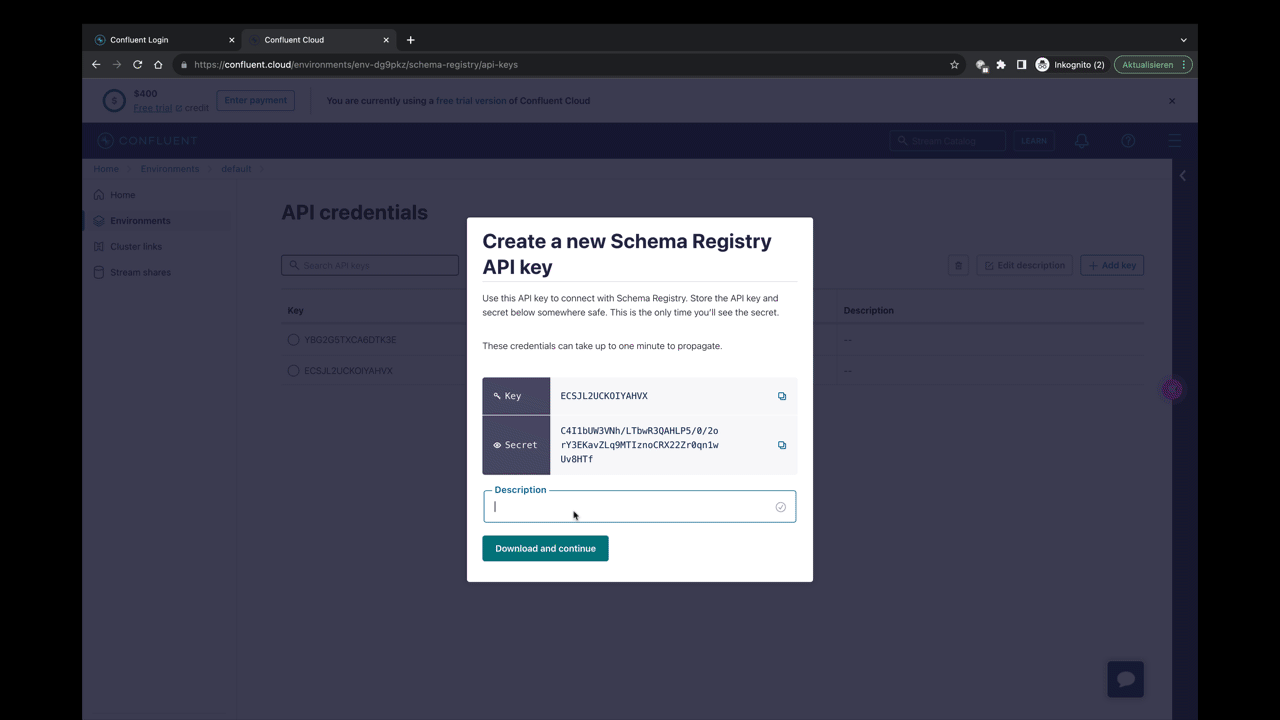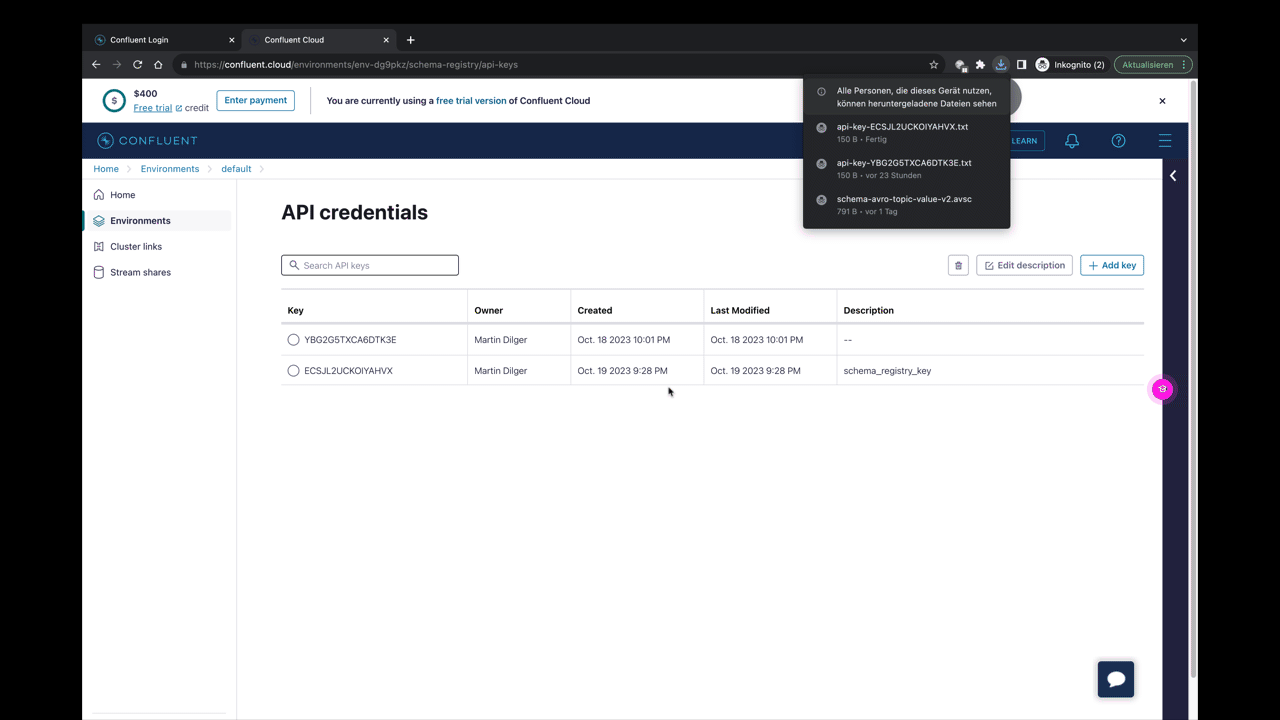
Für die Schema Registry benötigen wir eine eigene ClientId und ClientSecret die in der Konfiguration hinterlegt werden müssen.
spring.kafka.properties.schema.registry.basic.auth.user.info: <key>:<secret>
Die ClientId kann einfach über die Oberfläche generiert werden.
Nachdem wir den Code generiert haben kann die generierte Klasse direkt in einem KafkaConsumer verwendet werden.
@Component @KafkaListener(groupId = "avro-test", topics = ["avro-topic"]) class KafkaAvroConsumer { @KafkaHandler fun consume(message: orders) { println(message) } }
Zum Experimentieren implementieren wir zusätzlich einen einfachen KafkaProducer und kombinieren diesen mit einem Scheduler, der jede Sekunde ein neues Record publiziert.
@Component class KafkaAvroProducer(var kafkaTemplate: KafkaTemplate<String, orders>) { @Scheduled(fixedDelay = 1000L) fun produce() { println("Producing new order") kafkaTemplate.send("avro-topic", orders().apply { this.itemid = UUID.randomUUID().toString() this.orderid = 5 this.ordertime = LocalDateTime.now().toEpochSecond(ZoneOffset.UTC) this.address = ksql.address().apply { this.city = "München" this.zipcode = 80805 this.state = "none" } }) } }
Das Spring Boot Projekt befindet sich hier auf github. Die Avro Implementierung befindet sich auf dem Branch avro
Neugierig geworden? Mit unserer Expertise im Bereich Kafka, Kotlin und Spring bieten wir die Möglichkeit ihre Entwicklung zu beschleunigen und produktiver zu machen. In unserem kostenlosen Kennenlern-Call haben Sie zudem die Möglichkeit, kostenlos erste Fragen zu platzieren.