Confluent Cloud - Komplettes Setup mit Spring Boot (inkl. Testdaten) in weniger als 5 Minuten

Wir beraten Anbieter-neutral und finden mit Ihnen das beste Setup und Angebot für Ihre Streaming basierte Umgebung auf Basis Ihrer Anforderungen.
Ein Angebot mit beeindruckeneden Möglichkeiten im Kafka Umfeld ist Confluent Cloud
In diesem kurzen Blogeintrag möchten wir Ihnen Schritt für Schritt aufzeigen, wie ein einfaches Setup mit Spring Boot und Confluent Cloud aufgesetzt werden kann und welche Möglichkeiten Sie damit haben.
Das Setup dauert nicht länger als 5 Minuten.
Cluster Setup
Zunächst erstellen wir uns einen einfachen Cluster in der Basis-Konfiguration. Als Cloudprovider wählen wir AWS in der Region Frankfurt.
Confluent erlaubt es die Zahlungsdaten zu überspringen so dass wir einfach mit dem automatisch bereitgestellten Testing-Budget arbeiten können.

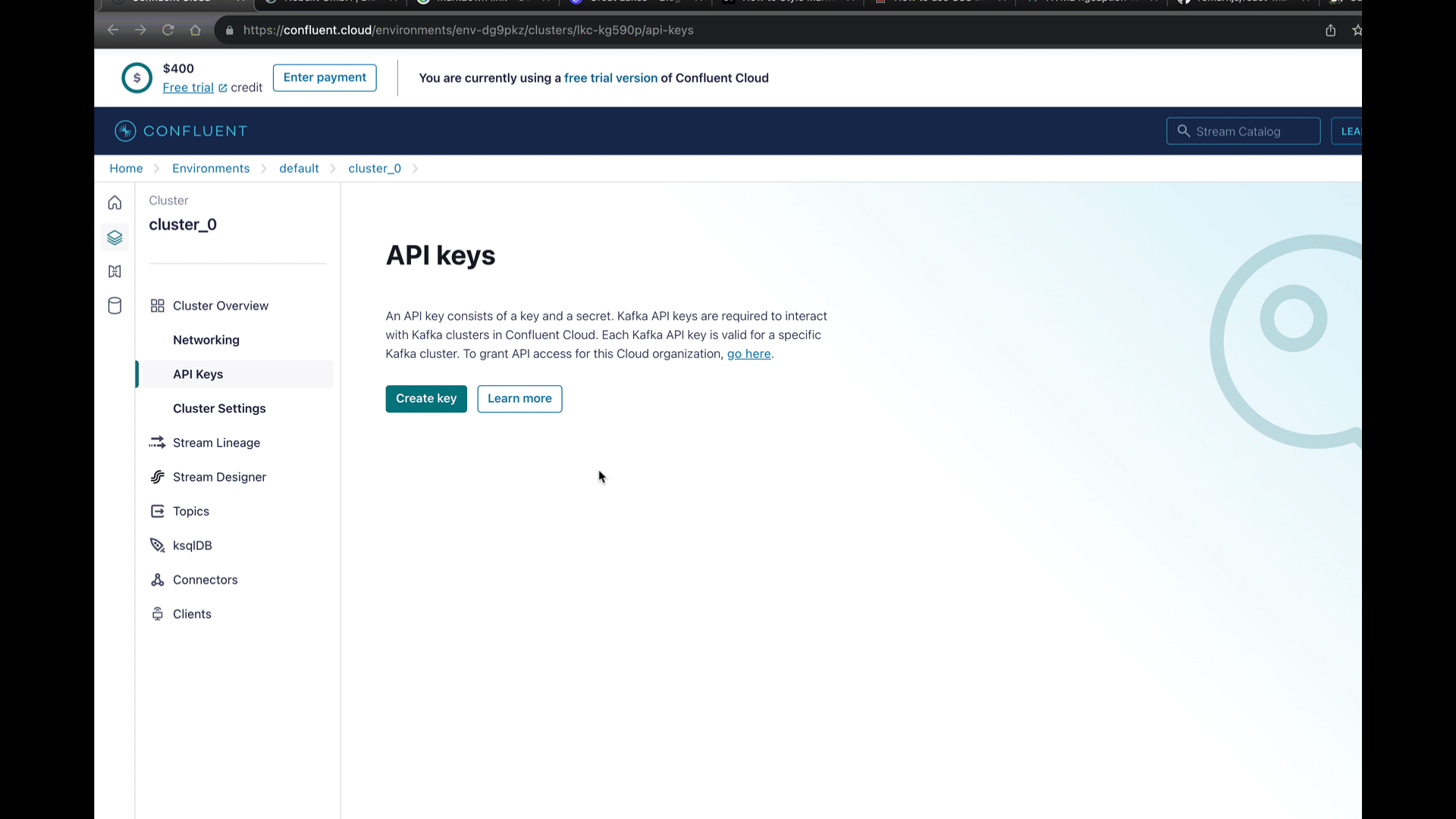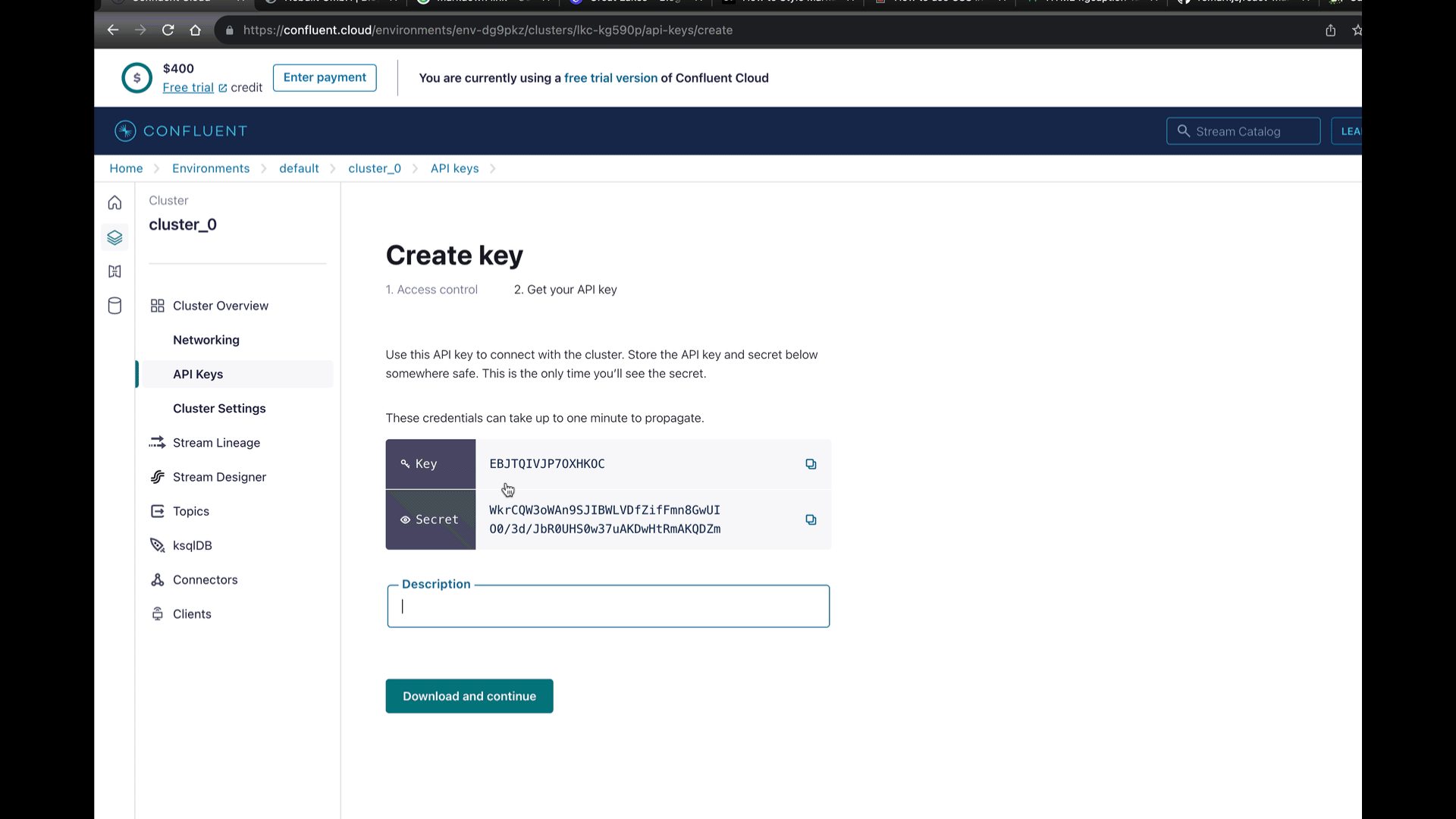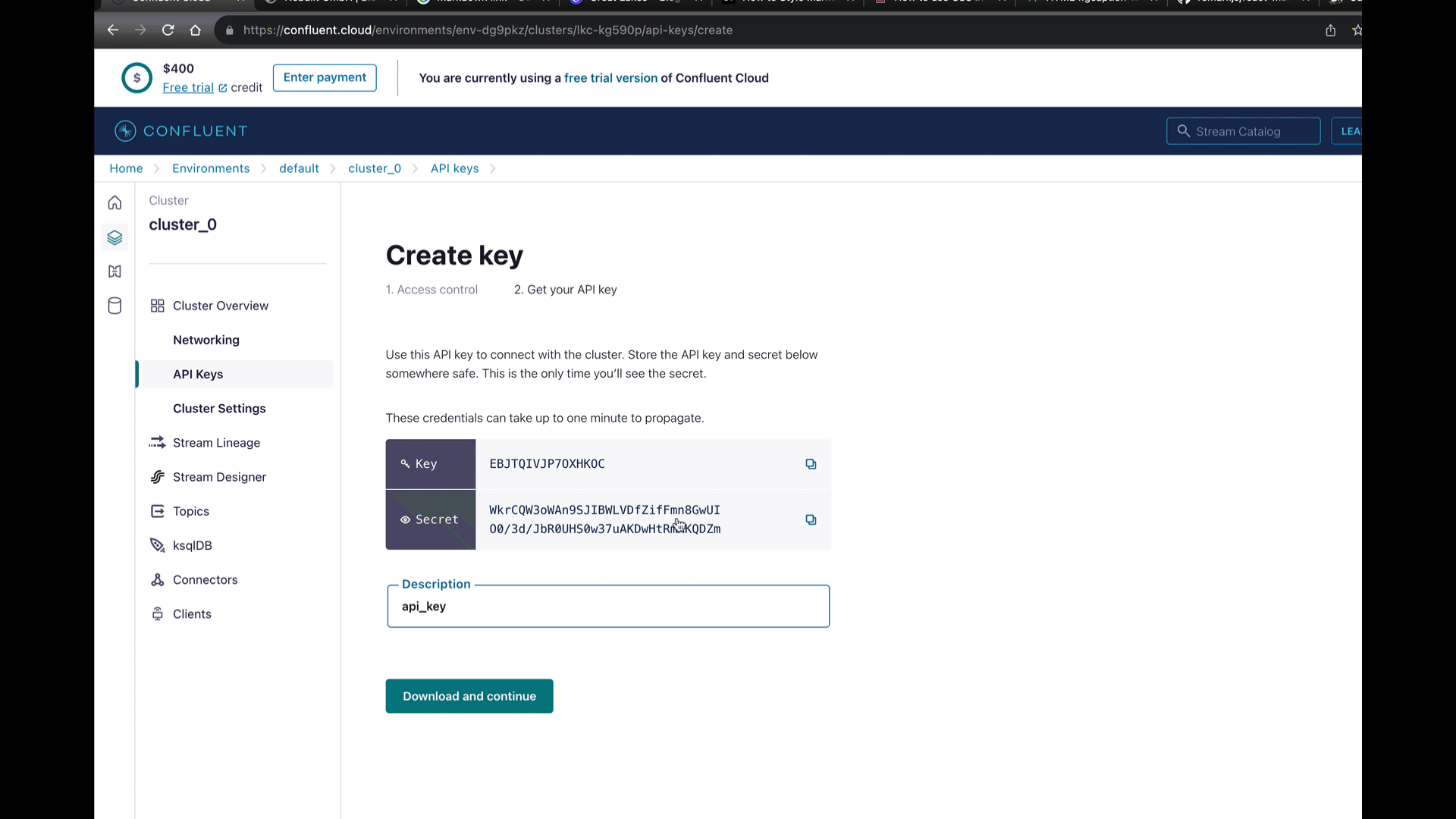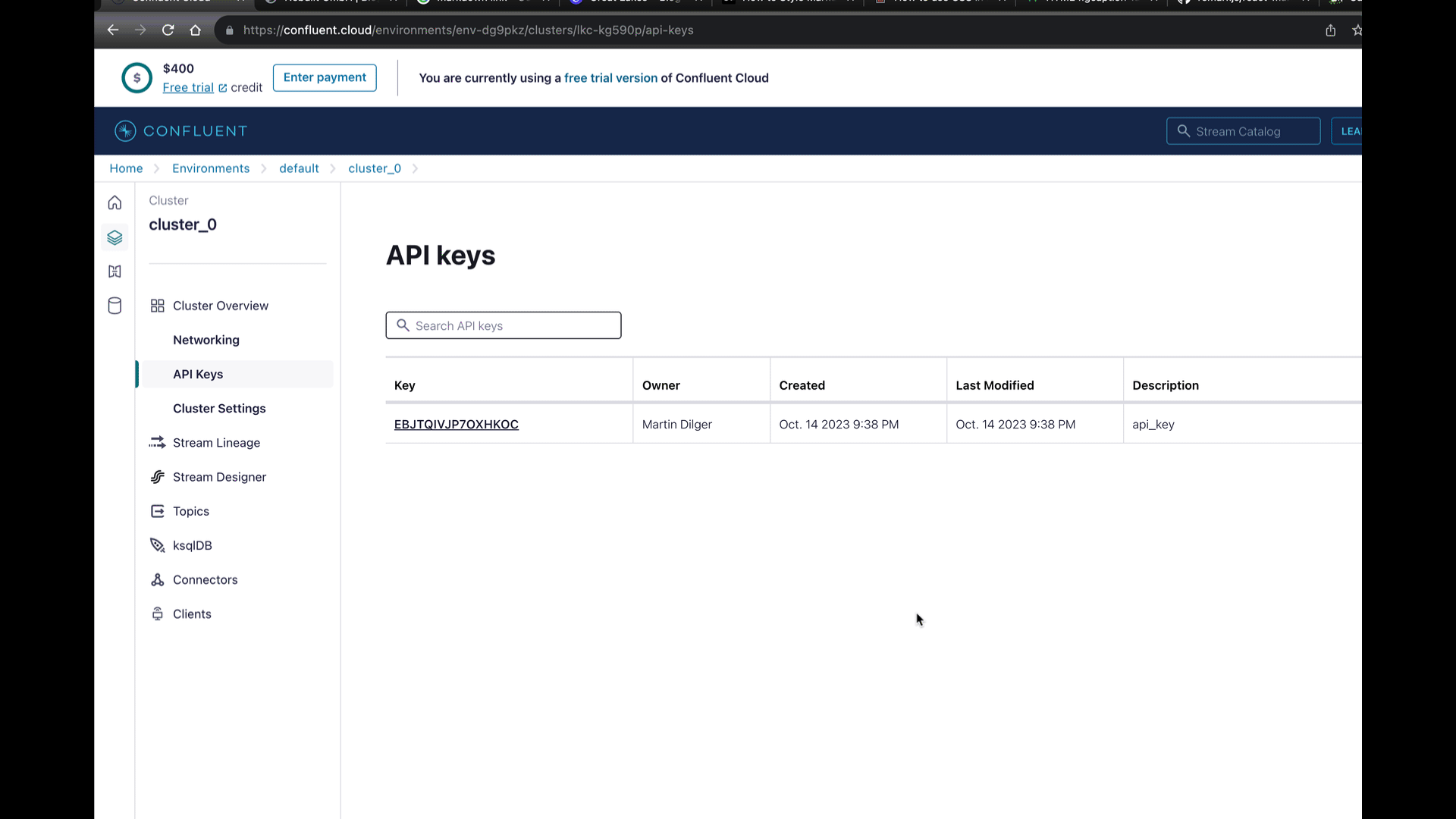
Für den Zugriff auf den Cluster benötigen wir einen API Key den wir uns direkt in der Oberfläche erstellen.
Spring Boot Setup
Unser Client ist ein einfacher Spring Boot Client den wir mit Spring Boot Initializr initialisieren.
Wir konfigurieren:
- Spring Web
- Spring for Kafka
- Spring Actuator
als Pakete.
WIr importieren das Projekt anschließend in IntelliJ und führen es testweise aus.
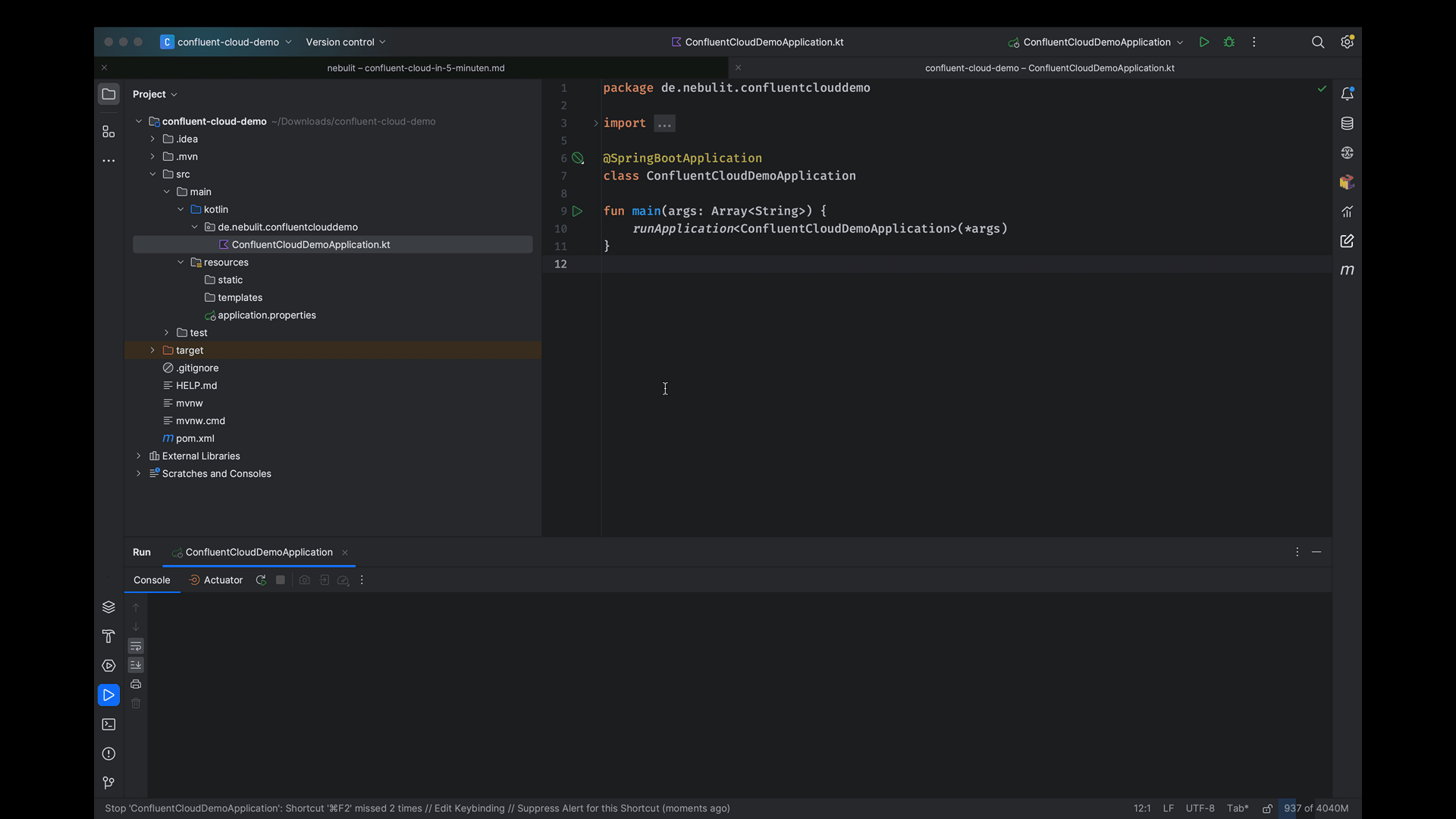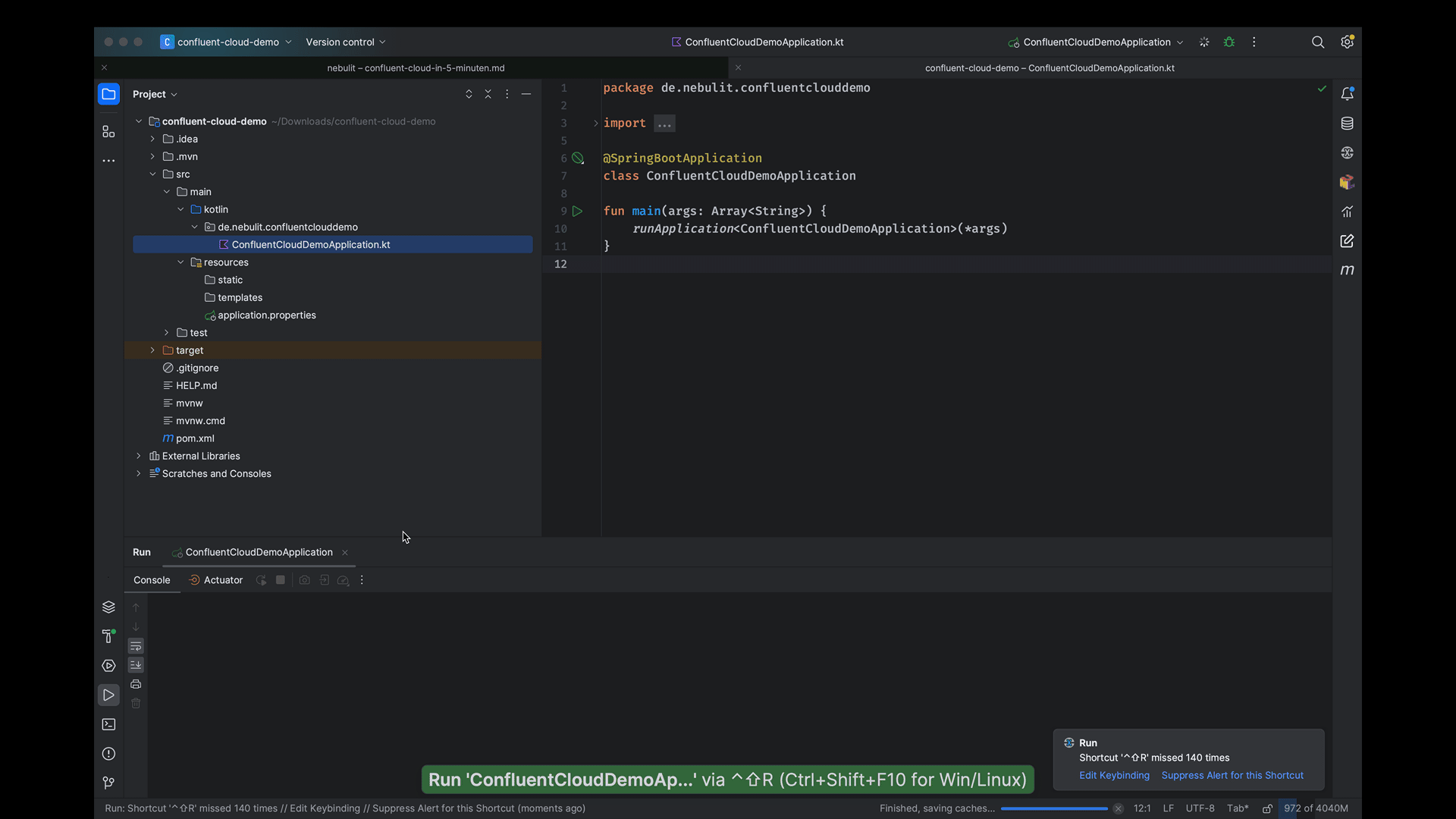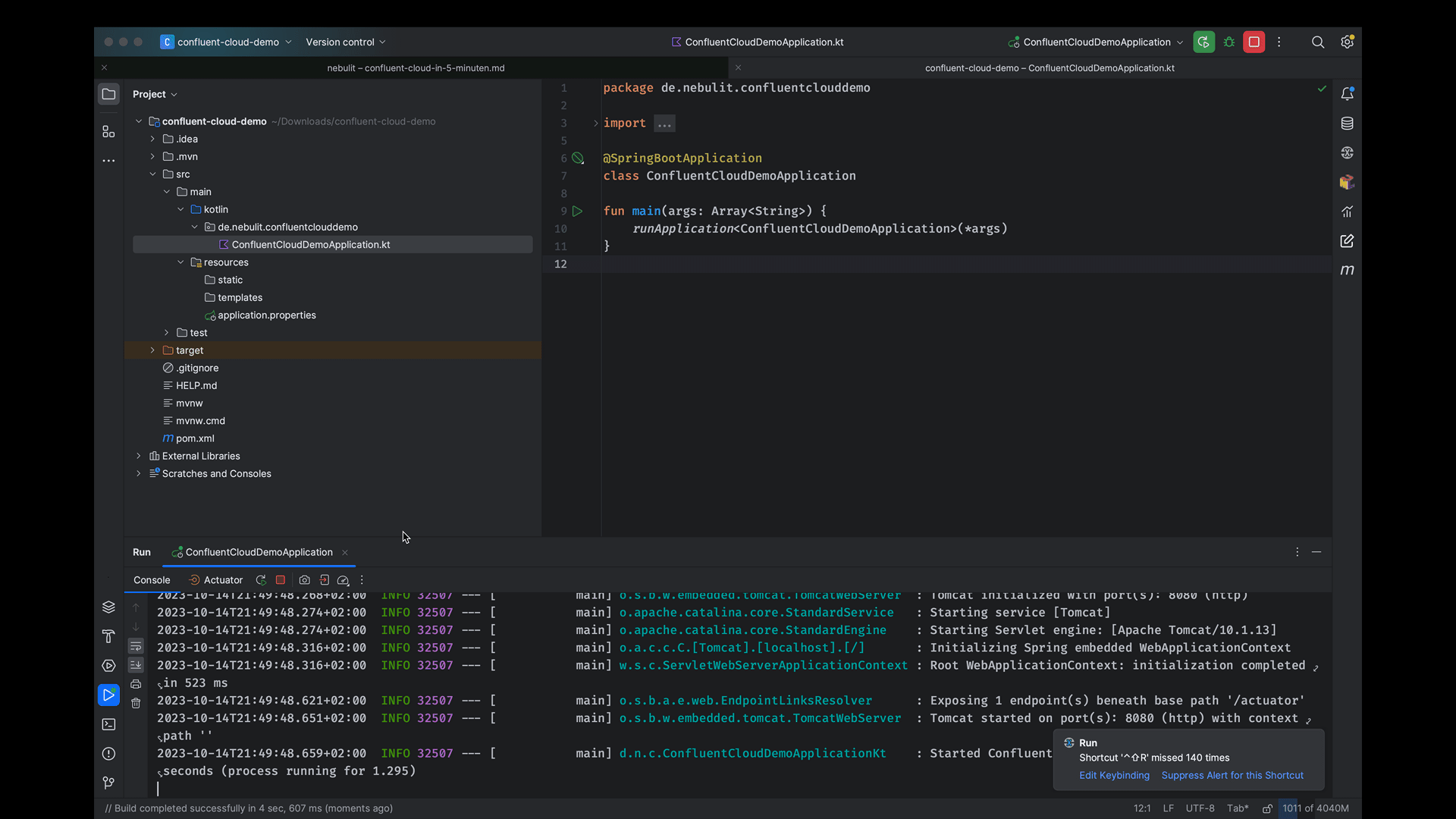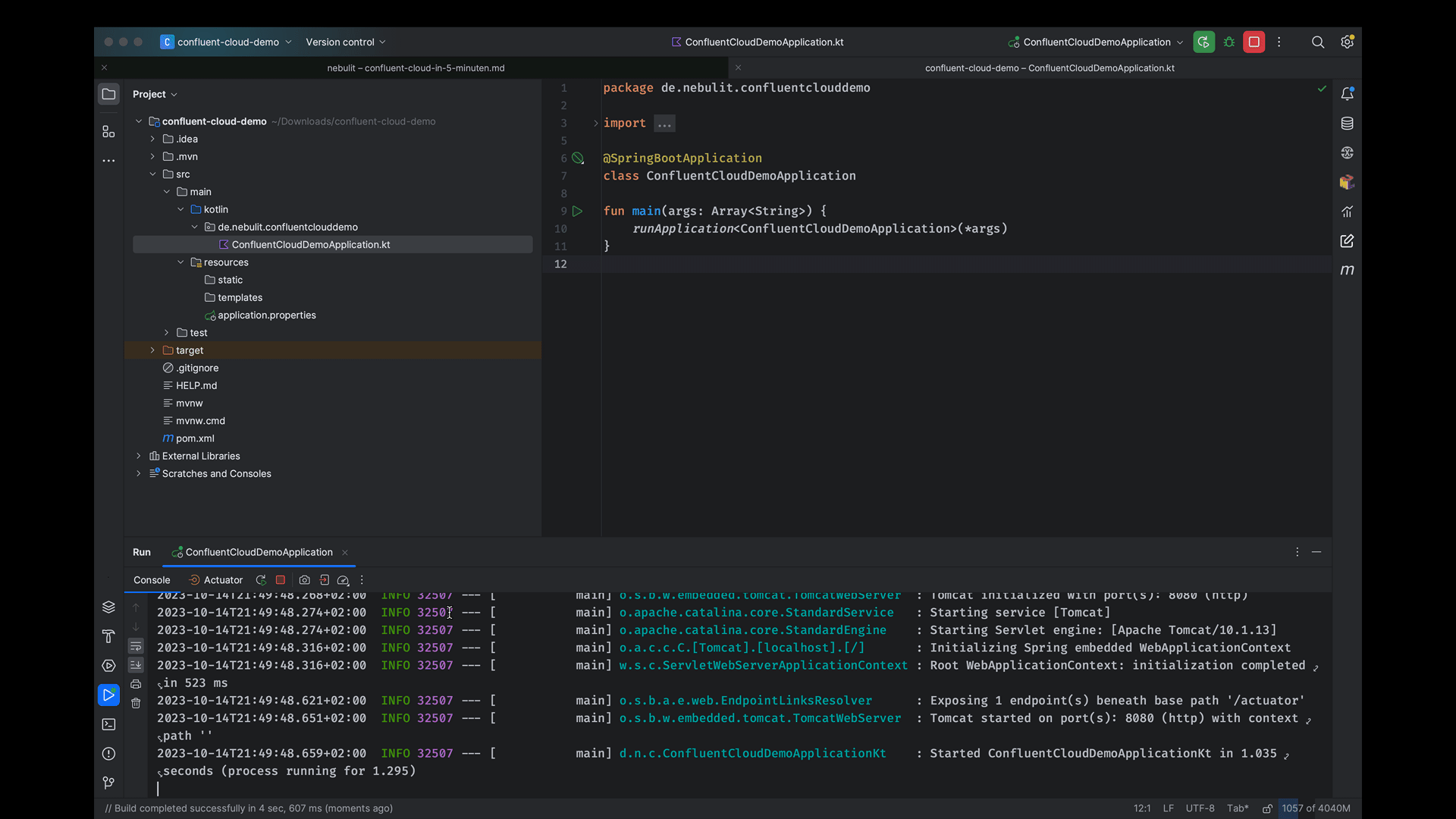
Für das Setup kopieren wir die Konfiguration aus der Confluent-Cloud Oberfläche und nehmen ein paar kleinere Anpassungen vor. Beispielsweise müssen wir damit die AutoConfiguration greift die spring.kafka.bootstrap-servers Property korrekt konfigurieren.
Confluent stellt diese Property als spring.kafka.properties.bootstrap.servers bereit.
# Required connection configs for Kafka producer, consumer, and admin spring.kafka.properties.sasl.mechanism=PLAIN spring.kafka.bootstrap-servers=<url> spring.kafka.properties.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username='<key-key>' password='<api-secret>'; spring.kafka.properties.security.protocol=SASL_SSL # Best practice for higher availability in Apache Kafka clients prior to 3.0 spring.kafka.properties.session.timeout.ms=45000 # Required connection configs for Confluent Cloud Schema Registry spring.kafka.properties.basic.auth.credentials.source=USER_INFO spring.kafka.properties.basic.auth.user.info={{ <key-key> }}:{{ <api-secret> }} spring.kafka.properties.schema.registry.url=https://psrc-do01d.eu-central-1.aws.confluent.cloud
Anschließend reicht es einen einfachen Kafka Consumer zu implementieren und als Spring Component bereitzustellen.
@Component @KafkaListener(groupId = "test", topics = ["test-topic"]) class KafkaConsumer { @KafkaHandler fun consume(message: String) { println(message) } }
Topic Konfiguration
Wir legen im nächsten Schritt über die Confluent Oberfläche das fehlende Topic an und schicken manuell ein Test Record.
Test Data Source Connector
Ein großer Vorteil bei der Verwendung von Confluent ist die integrierte Nutzung des gesamten Kafka Ökosystems. Um beliebig viele Testdaten für unser Topic zu generieren können wir einfach nur einen Data-Gen Source Connector mit dem Topic verknüpfen und die Daten fangen sofort an zu fließen.
Technisch arbeitet hier ein Kafka Connect Cluster und wir konfigurieren einen Connector dafür.
Fazit
Es ist kinderleicht eine Kafka Umgebung mit Confluent Cloud aufzusetzen um erste Experimente damit zu wagen.
Das Spring Boot Projekt befindet sich hier auf github.
Im nächsten Artikel betrachten wir die Schema Registry und Avro in Spring Boot.
Neugierig geworden? Mit unserer Expertise im Bereich Kafka, Kotlin und Spring bieten wir die Möglichkeit ihre Entwicklung zu beschleunigen und produktiver zu machen. In unserem kostenlosen Kennenlern-Call haben Sie zudem die Möglichkeit, kostenlos erste Fragen zu platzieren.