Wie modelliert man asynchrone Prozesse mit Eventmodeling
Hintergrund
Jedes komplexe System kann als eine Abfolge einfacher Schritte modelliert werden. Dies gilt auch für die Modellierung und Implementierung von automatisch ablaufenden Hintergrundprozessen im Eventmodell.
Warum schreibe ich diesen Artikel?

Die Anfrage stammt aus der Eventmodeling-Community. Es gibt viel Theorie zu Eventmodeling, Eventsourcing und wie das alles funktioniert, aber nur sehr wenige Beispiele dafür. Daher veranstalte ich regelmäßig Webinare, in denen wir in den Code eintauchen und unter die Motorhaube blicken. Genau deswegen schreibe ich auch das Buch "Understanding Eventsourcing". Den Hilferuf oben habe ich gehört und stelle hier eine mögliche Modellierung des beschriebenen Systems vor und natürlich auch die Umsetzung.
Am Ende des Artikels findest du den Link zum Miro-Board und den Source-Code auf Github.
Was wir in diesem Artikel machen
- Wir modellieren die Software in Miro.
- Wir übersetzen das Modell in Code.
- Wir nutzen State-of-the-Art-Technologien (Kotlin 2.x, Spring Boot, Spring Modulith und Axon).
Was du in diesem Artikel lernen wirst
- Wie modellierst du asynchrone Prozesse mit Eventmodeling?
- Wie werden die modellierten Prozesse in Code überführt?
- Wie sehen fachliche Test Cases für asynchrone Prozesse aus?
Der Use Case
Wir haben ein System, das im Hintergrund auf Anfrage verschiedene Reports generiert, beispielsweise als PDF, und diese Reports schlussendlich zusammenfasst und dem User liefert. Die Generierung dauert natürlich viel zu lange (im schlimmsten Fall einige Minuten), und die UI des Users steht in der Zwischenzeit. Wir werden das ein wenig eleganter lösen.
Das Modell
Wir modellieren in Miro, meinem Tool der Wahl, da sowohl Techniker als auch die Fachseite sich schnell in Miro einfinden und unser Eventmodeling-Tooling komplett auf Miro basiert. Zusätzlich sind wir nicht auf fremde Tools und deren Installation angewiesen, sondern können im Prinzip sofort loslegen.
Angenommen, es sollen Reports über die besten Brauereien in verschiedenen Ländern erstellt werden, als PDF. Wir nutzen hierfür die Open Brewery API. Dafür übergibt der User die gewünschten Länder über einen HTTP API Call an unser System. Wir generieren eine Swagger-UI direkt aus dem Eventmodell. Du kannst die Anwendung (am Ende des Artikels verlinkt) direkt starten und damit spielen.
Die Anwendung startet mit der Generierung und erstellt ein PDF pro Land, in dem alle Brauereien aufgelistet sind. Am Ende werden alle PDFs zusammengefasst und als ein Zip-Archiv zum Download angeboten.
Im ersten Schritt ("Storming Phase") sammeln wir die Events.

Die erste Storyline
Das Event "Archive Requested" deutet an, dass ein neuer Report angefordert wurde. Sobald die asynchronen Hintergrundprozesse gelaufen sind, werden die erzeugten Reports gespeichert ("Report Stored"). Sobald alle Prozesse durchlaufen sind, wird das Archiv erstellt ("Report Archive Stored"). Ein weiterer Schritt besteht in der Publizierung des Archivs zum Download ("Archive Published"). Wir verzichten bewusst auf Fehlerbehandlung, um das Modell im ersten Schritt möglichst einfach zu halten.
Im nächsten Schritt definieren wir Screens, Commands, Processors und Readmodels, wie hier im Workshop-Format beschrieben.
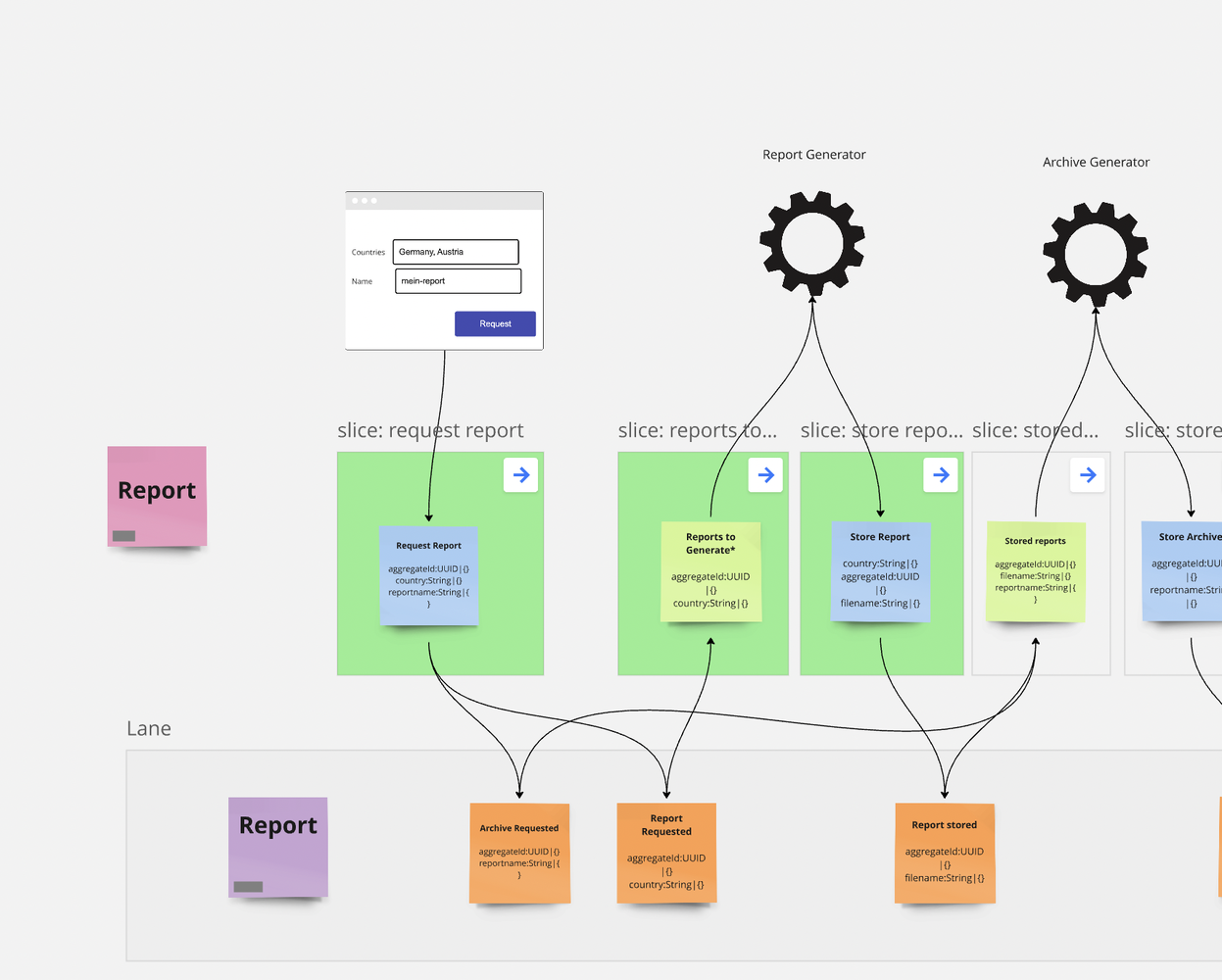
Der modellierte Workflow
Das Modellieren des kompletten Flows dauert mit dem Miro-Tooling nur wenige Minuten, da die Felder einfach zwischen den Elementen kopiert werden können. Gleichzeitig prüft das Tooling, dass die Daten korrekt verwendet werden, mit dem Information-Completeness-Check. Das Modell in Miro findest du übrigens hier.
Die Übersetzung in Code
Wir nutzen den Code-Generator aus dem Tooling und generieren Slice für Slice. Jeder umgesetzte Slice wird im Modell grün markiert. Wir arbeiten mit einer klassischen Vertical-Slice-Architektur, d.h. jedes Feature ist ein eigenes Package. Wir nutzen zusätzlich Spring Modulith, um die Abhängigkeiten zwischen den Packages zu überwachen.
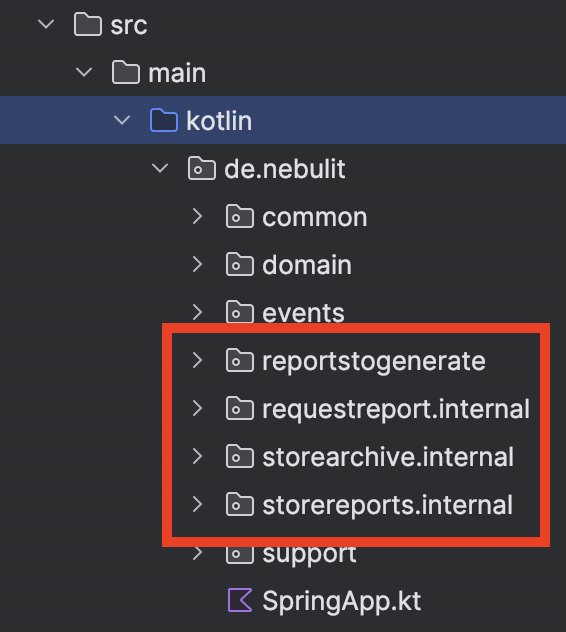
Übrigens bieten wir einen kostenlosen Spring Modulith Onlinekurs - bei Interesse schreibt mich gerne per DM an und du bekommst Zugriff.
Tests
Unterhalb jedes Slices definieren wir zusätzlich fachliche Testcases als "Given / When / Then", um die Business-Regeln für alle verständlich zu formulieren.
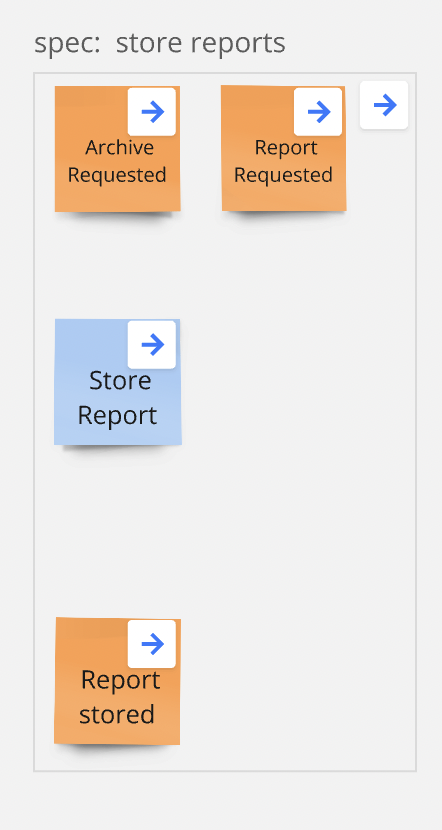
Given:
- Der User hat bereits ein Archiv angefragt, daher sind "Archive Requested" und "Report Requested" Events im System gespeichert.
When:
- Angenommen, das "Store Report" Command wird jetzt ausgeführt.
Then:
- Dann erwarten wir, dass das "Report Stored" Event im System gespeichert wurde, und zwar mit den Daten aus dem Command.
Implementierung in Axon
80% des Codes (inklusive Tests) kann direkt aus dem Modell generiert werden. Wir fokussieren uns daher in den meisten Fällen komplett auf die Business-Logik. Wir generieren ebenfalls alle Events direkt aus dem Eventmodell. Die Implementierung der einzelnen Command Handler ist relativ unkompliziert und geradlinig.
Beispielsweise verarbeitet das "ReportAggregate" hier das RequestReportCommand und speichert sowohl das ArchiveRequestedEvent, das später auch als Startpunkt für die Automatisierung dient, als auch die einzelnen ReportRequestedEvents.
@CreationPolicy(AggregateCreationPolicy.ALWAYS) @CommandHandler fun handle(command: RequestReportCommand): CommandResult { AggregateLifecycle.apply(ArchiveRequestedEvent(command.aggregateId, command.reportname)) command.country.split(",").forEach { AggregateLifecycle.apply(ReportRequestedEvent(command.aggregateId, it)) } return CommandResult(command.aggregateId, AggregateLifecycle.getVersion()) }
Dass hier ein String als kommaseparierte Liste übergeben wird, ist sicherlich diskussionswürdig, für den Start aber durchaus möglich. Der Command-Handler liefert ein CommandResult, das neben der AggregateId auch die aktuelle Version des Aggregates bereitstellt. Der Default in Axon ist einfach die AggregateId als String.
Wie aber werden jetzt Automatisierungen implementiert?
Ich unterscheide prinzipiell zwischen Stateful- und Stateless-Automatisierungen:
- Stateful: Die Automatisierung hält ihren eigenen State und entscheidet selbst, wie eingehende Daten verarbeitet werden.
- Stateless: Die Automatisierung lädt State immer live aus einer Projektion oder dem Eventstream.
Für die Erstellung des Archivs bietet sich eine Stateful-Automation an. Die Automation sammelt alle "Report Stored" Events und gleicht diese mit den "Report Requested Events" ab. Sobald alle angeforderten Reports erstellt wurden, kann das Archiv ebenfalls erstellt werden. Die Logik ist trivial und hier implementiert.
private fun processArchive() { if (requestedCountries.size == processedCountries.size) { // Alle Länder verarbeitet val fileName = zipper.zipFiles(filenames, File.createTempFile(reportname, ".zip").absolutePath) commandGateway.send<StoreArchiveCommand>( StoreArchiveCommand(aggregateId = this.aggregateId, reportname = fileName) ) } }
Die Automatisierung gleicht für jeden erstellten Report ab, ob die Anzahl der ursprünglich angeforderten Reports den bereits erstellten Reports entspricht. Jedes Mal, wenn ein Report fertiggestellt wurde, aktualisiert unsere Automatisierung ihren State in Eigenregie.
@SagaEventHandler(associationProperty = "aggregateId") fun on(event: ReportStoredEvent) { aggregateId = event.aggregateId processedCountries.add(event.country) filenames.add(event.filename) processArchive() }
Sobald alle angeforderten Reports erstellt wurden, kann das Archiv erstellt werden. Technisch ist dies eine Umsetzung des "TODO Patterns". Das TODO ist "Archiv erstellen" und kann erst abgehakt werden, wenn das ReportArchiveStored Event im System gespeichert ist.
@EndSaga @SagaEventHandler(associationProperty = "aggregateId") fun on(event: ReportArchiveStoredEvent) { }
Technisch nutzen wir hierfür die Saga-Integration in Axon, die die Persistierung des States automatisch übernimmt. Die komplette Implementierung der Automatisierung ist hier zu finden.
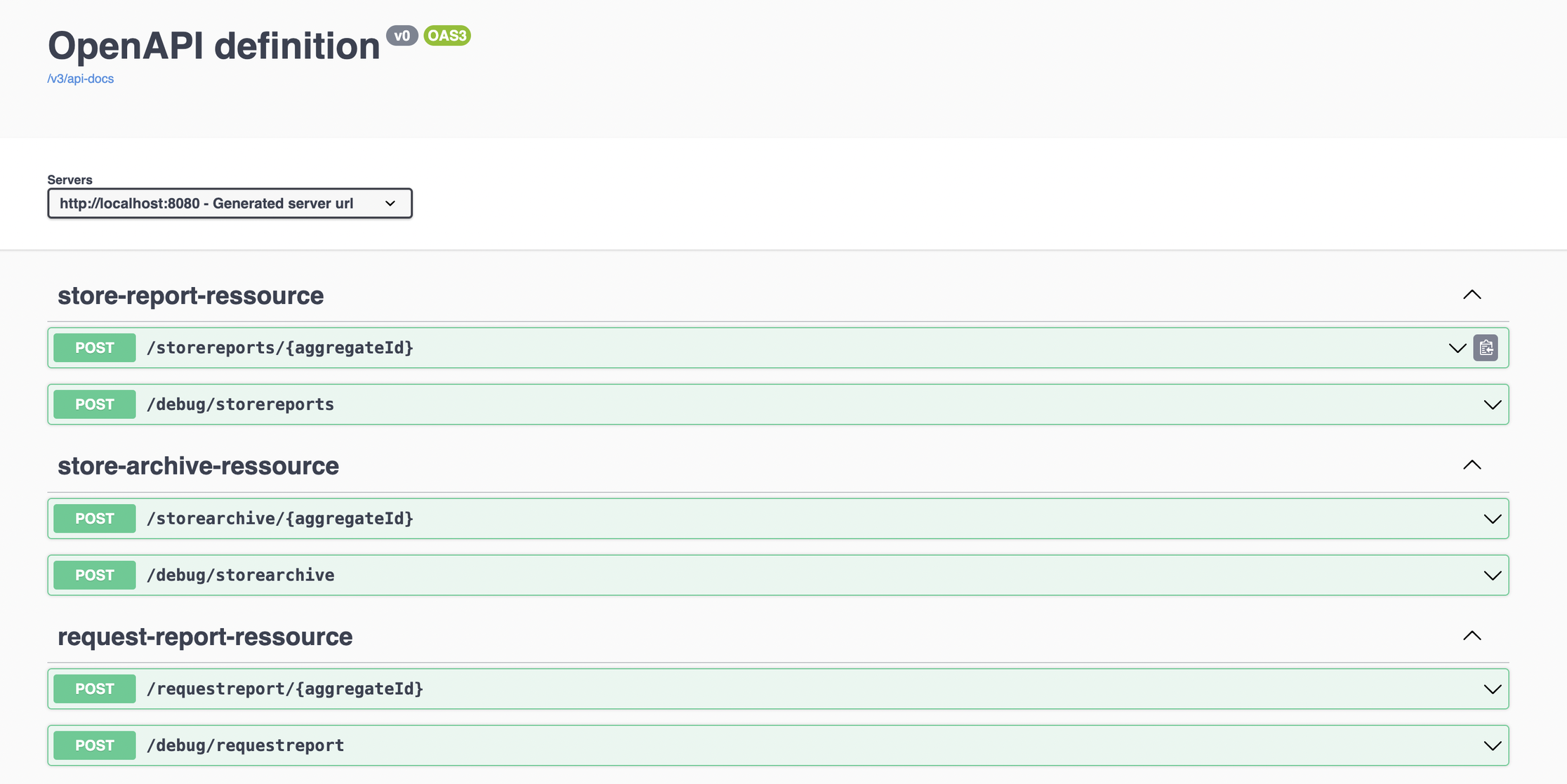
Starten der Anwendung
Die Anwendung ist direkt startbar und kann über die generierte Swagger UI bedient werden.
Zusammenfassung
Im nächsten Artikel betrachten wir die Integration mit der UI und wie die asynchronen Prozesse mit der UI über Server Sent Events und Axon Subscription Queries kommunizieren können.
Links
Wir unterstützen bei der Einführung und Arbeit mit eventbasierten Architekturen
Die Einführung von eventbasierten Architekturen ist mit vielen Fallstricken verbunden und allzu oft mit zeitaufwendigem Try & Error. Wir unterstützen in den ersten Wochen in der Planung und auch Umsetzung erster Systeme und definieren gerne zusammen mit Architektur und den Teams die grundlegende Architektur.